Feature Fetch Optimization
In this post, I’ll deep dive into how I engineered a parallel execution system to fetch features from DynamoDB and Feature Service, and optimized the feature request lifecycle to achieve an 8× speedup.
Overview
Fetching features used to be one of the slowest parts of building our machine learning models. For example, getting features for one million samples could take up to 72 hours, an incredibly long time to wait. At first glance, the scale of the task seems to explain the delay: each user needs about 50 different groups of features (feature families), and each group contains around 60 features. That adds up to 50 million feature family fetches and a total of 3 billion individual features for the dataset. It’s true that this is a lot of data, but for big companies handling huge amounts of information measured in petabytes, waiting three days for feature preparation simply isn’t practical, even with limits on resources. This reality prompted me to optimize the feature fetching process to make it dramatically more efficient and faster.
Feature Fetch is a long-running process consisting of four major components: RecordsIterator, DynamoDB Fetcher, Feature Service Fetcher, and File Writer.
- RecordsIterator: Iterates over the records for which we need to fetch features and passes them to the DynamoDB Fetcher.
- DynamoDB Fetcher: Retrieves features from DynamoDB.
- Feature Service Fetcher: Retrieves features from the Feature Service.
- File Writer: Writes the fetched features to files in batches.
We identified critical inefficiencies in the old flow (discussed in the next section) and solved them by designing a new distibuted and multi-processing architecture with advanced optimization, accelerating feature fetch by approximately 8x reducing the time for 1M samples from 72 hours to around 10 hours. The new Fast Feature Fetch system is also significantly more stable and scalable (constrained by resources, not the framework), more efficient, and more cost-effective. Throughout this post, I’ll also mention additional optimizations that could further reduce the time by another 2x.
Major Inefficiencies in Old Flow
In the old flow, the RecordsIterator generates records that are passed to the DynamoDB Fetcher. For feature families with cache hits, these features are immediately passed to the File Writer component. For cache misses, events are routed to the Feature Service Fetcher, which retrieves features from the Feature Service and then passes them to the File Writer. Once the File Writer aggregates features for a batch of users, it writes the complete batch to the file system.
The fundamental problem is that all these components run serially in a single process. The DynamoDB Fetcher and Feature Service Fetcher must wait idle while the File Writer is writing to disk. Similarly, while other components are working, the File Writer sits idle. This sequential execution is clearly inefficient and not scalable. Apart from these issues, there are few more in each category which we will see in the upcoming sections.
Inefficiencies in DynamoDB Fetcher
There are several critical inefficiencies in the DynamoDB Fetcher:
-
Incorrectly Assuming DynamoDB Fetcher is I/O Bound
We initially set a default batch size of 100, assuming the DynamoDB fetcher was I/O bound. However, our profiling revealed it’s actually CPU bound. The time spent creating keys and processing batch requests exceeds the time spent fetching items from DynamoDB itself. Even increasing the batch size to 1000 didn’t improve performance proportionally. Through analysis, we discovered that a DynamoDB fetcher running on a single CPU core won’t see performance improvements beyond a connection pool size of 3 (when using shared connections and async requests). With this optimal pool size of 3, a single processor can handle at most 8,000 requests per second, note: this is after implementing all possible code optimizations.
-
Creating DynamoDB Client for Each Feature Request
@asynccontextmanager async def _create_client(): async with self.session.create_client("dynamodb", ...) as client: yield client async def get_feature_per_user(self): async with _create_client() as client: response = await client.get_item(...)In the code above, a new DynamoDB client is created for every single feature request. This is extremely inefficient, the overhead of creating and destroying clients for each request becomes a major bottleneck. The solution is to create the client once and reuse it across all requests. Additionally, we can share a single connection pool across all requests, further reducing overhead.
-
Not Utilizing Single Request Read Capacity
DynamoDB allows us to read up to 100 records and 25MB of data per request via
batch_get_item. However, when fetching at the user level, we were only utilizing about less than 50% of this capacity per request. While this might seem like a minor optimization superficially, the reality is that creating requests and parsing responses takes significant CPU time. By batching multiple users’ feature families into a single request (up to the 100-record or 25MB limit), we effectively reduce the number of request/response cycles. This reduces both the number of parsings and the number of in-flight requests. We implemented retry mechanisms to handle edge cases where data exceeds 25MB, though in practice, we’ve never hit these retry cases.
Inefficiencies in Feature Service Fetcher
-
Unnecessary Excessive Feature Requests
In the old flow, we split each user’s feature families into groups of 3 per request to the Feature Service. This approach made sense for inference, where we want to minimize latency for a single user by parallelizing requests. However, for batch feature fetching, the goal is different, we want to optimize throughput for all users in the batch, not minimize individual user latency.
Consider the math: With 45 feature families per user split into groups of 3, we send 15 requests per user. For 1,000 users, that’s 15,000 requests. The Feature Service runs a synchronous Flask server where each request blocks a thread. The infrastructure is designed with 36 pods, each with 6 effective CPUs, 20 workers, and 150 threads to handle such a huge throughput. However, CPU utilization often hovered around 40%, most CPU cycles were spent either idle or managing the pool of thousands of concurrent requests rather than doing actual computation. Reducing these number of requests would allow the CPUs to spend more time on actual feature computation rather than request management overhead.
-
Slow or I/O-Bound Feature Requests
Some feature families are inherently slow. For example, event features require reading from an Amazon RDS database with around 100 billion rows, making this is extremely slow and completely I/O-bound. Similarly, for Kenya, we process a large volume of messages where regex operations (CPU-bound) take considerable time.
Here’s the problem: If we include slow feature families in the same request as fast ones, the entire request takes longer as all feature families in a request is executed sequentially. To make it much worser, our feature service is synchronous nature. So if multiple I/O bound requests are in the same batch, they execute sequentially. This means batching all feature families together (as planned above) would force all slow requests to execute one after another, dramatically increasing the total time to fetch features for the batch.
-
Synchronous Nature of Feature Service
The Feature Service uses a synchronous Flask server with synchronous REST APIs. Each incoming request blocks a thread. For a typical user, approximately 30% of processing time is spent waiting for I/O from S3, RDS, and other sources.
While converting the Feature Service to async would be relatively straightforward, it wouldn’t solve the fundamental problem. It would just shift the bottleneck to the RDS database, which is already slow. Overwhelming RDS with more I/O requests would cause slowness, timeouts, and IOPS-related issues. Upgrading the database to a larger instance with more IOPS would cost thousands of dollars. Even then, the GP2 storage type we use has a hard limit of 64,000 IOPS, which is insufficient for the throughput we might have. Moving to faster storage (like Provisioned IOPS or io2) would require significant effort and cost. Given these constraints, we had to work with the synchronous nature of the Feature Service.
Inefficiencies in File Writer
-
Synchronous File Writer
The File Writer must write to the local file system and then synchronize to S3 for remote backup. This process takes approximately 2-3 minutes for a chunk of 1,000-5,000 users. In the old single-threaded architecture, this meant all other components (DynamoDB Fetcher and Feature Service Fetcher) sat idle during writes. Even in a new parallel system, synchronous file writing would be a bottleneck if we scale up the DynamoDB fetcher and most records have cache hits, the write operations would struggle to keep up with the fetch rate.
New Architecture
To tackle all the inefficiencies outlined above, we designed a completely new distributed and parallel system architecture (Image 1.1) that is highly scalable and efficient. We call this system Fast Feature Fetch throughout the rest of this post. For this new architecture, we leveraged Ray for distributed computing. All the components and queues are implemented as Ray actors, enabling true parallelism and fault tolerance.
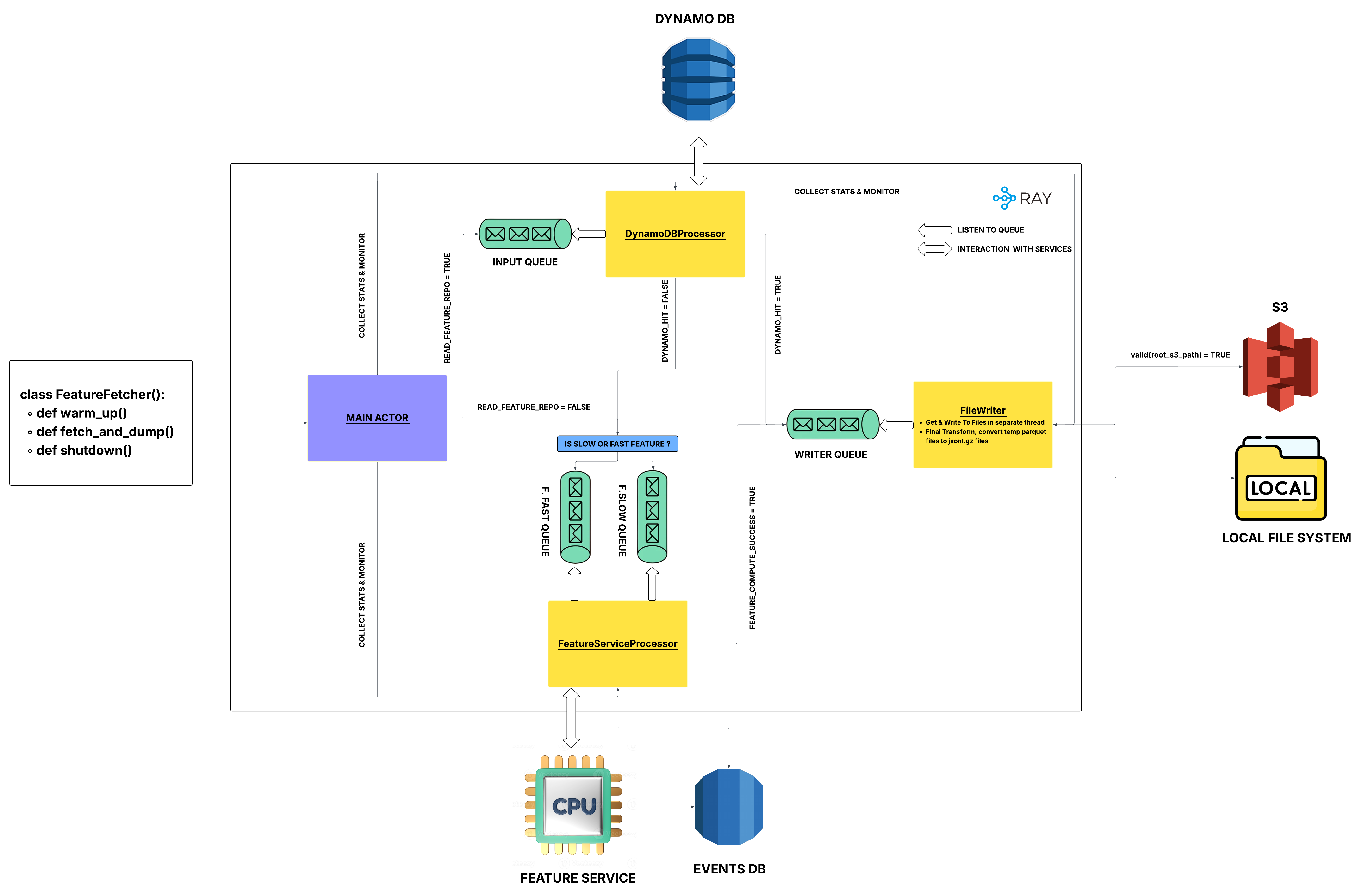
From the image, you can see we have four major actors and four queues:
- Main Actor: Orchestrates the entire run spawns worker actors, manages configuration, collects metrics, supervises failures, and coordinates graceful shutdown.
- DynamoDB Processor Actor: Listens to the input queue and fetches features from DynamoDB as soon as events are added to the queue.
- Feature Service Processor Actor: Listens to the feature service queues and fetches features from the Feature Service as soon as events are added.
- File Writer Actor: Buffers and writes outputs, performs intelligent batching, and handles the final data transform.
- Queues:
- Input Queue: Where feature fetch requests are placed to be fetched from DynamoDB.
- Feature Service Fast Queue: Where all feature families in each event are called in a single batch request (1 event → 1 batch feature request), allowing the features within the request to be computed sequentially but efficiently.
- Feature Service Slow Queue: Where each feature family mentioned in an event is fetched in separate requests that execute in parallel.
- Writer Queue: Where successfully fetched features are placed to be written to files.
All the above components are standalone actors that can be scaled horizontally based on our needs. Specifically, based on the data volume we need to fetch and the desired speed. The Main Actor serves as the coordinator, while other actors are workers.
Important note on scaling: Simply increasing the number of actors won’t automatically increase speed. The underlying services (DynamoDB, Feature Service, RDS database) must have adequate provisioning, sufficient pods, IOPS, and capacity, and must not be the limiting factor. Speed increases only when existing actors are already being used at full potential and the backend services can handle additional load.
For example:
- The Main Actor is lightweight, spending most of its time listening to worker actors and monitoring system health. Scaling it has no effect.
- The File Writer is mostly I/O-bound and constrained by disk operations. Since it’s already efficient with 1 CPU, scaling it horizontally doesn’t help.
- The DynamoDB Fetcher is CPU-bound when loaded with requests. Scaling it can increase speed, provided DynamoDB has sufficient read capacity provisioned.
Since all these are Python processes constrained by the GIL (Global Interpreter Lock), each actor can effectively use only 1 CPU core unless using multiprocessing inside the actor. Therefore, if CPU is the limiting factor, increasing the number of actors (and thus the number of processes) will increase throughput.
System Flow:
The actors work together in a producer-consumer pattern:
- The DynamoDB Processor and Feature Service Processor fetch features and place results in the writer queue.
- The File Writer consumes from the writer queue, buffers results, and writes to disk when the buffer is full.
- The cache file is updated with completed feature families, enabling resumability and incremental processing.
- Completed files are synced to remote storage (S3) for durability.
Parallelism at the Feature Family Level
To handle things in a truly parallel fashion, we can’t wait until all feature families for a user are completed. Unlike the old feature fetch where the smallest entity was a user, in Fast Feature Fetch, the smallest entity is a feature family. This means we can write fetched features as soon as we receive them, rather than waiting for all features for a user to complete. We’ll examine this design in detail when we discuss the Writer Actor.
Configuration Management
We use a pydantic config (FeatureFetchConfig) object that tracks how many actors need to be scheduled and stores all actor configurations and queue configurations. This config also serves as metadata to track the overall process.
New Feature Fetch API
Let’s look at how the new feature fetch system can be used:
config = FeatureFetchConfig(...) # Defines the system configuration
# This starts the feature fetch Ray system, initializes all actors and queues, and their clients.
# It also starts monitoring and logging.
with FastFeatureFetcher(config) as fetcher:
fetcher.warm_up() # Warms up the system
fetcher.fetch_features(records) # Fetches features for the records
Key points:
-
Context Manager: Using the context manager ensures the system is cleaned up properly when execution completes. Since we scale up backend services during execution, we need to descale them before exiting. If you don’t use the context manager, you must manually call
fetcher.shutdown()to gracefully shut down the system. -
warm_up(): This method warms up DynamoDB, Feature Service, and RDS databases by pre-scaling them to handle the expected load. -
fetch_features(records): This method starts the entire feature fetch system and processes all the provided records.
Warm-Up Step
This is a crucial step to ensure the system is ready to fetch features at maximum speed. During warm-up, the system performs several key operations:
-
DynamoDB Provisioning: Sets optimal read and write capacity for DynamoDB tables based on expected throughput. Internal calculations determine the appropriate values based on the number of records and desired completion time.
-
Feature Service Scaling: Sends sample requests to the Feature Service to trigger horizontal pod autoscaling (HPA) in the Kubernetes cluster, ensuring sufficient pods are available before the main workload begins.
-
RDS Database Scaling: Vertically scales RDS databases as needed to handle the increased read load. This scaling is particularly important because RDS must be scaled back down to normal levels once feature fetch completes to avoid unnecessary costs.
It’s critical to scale down resources in case of failures, shutdowns, or interruptions. To handle this, we implemented shutdown handlers that ensure cleanup happens even during unexpected terminations.
Shutdown Handler
To ensure resources are always cleaned up, we register handlers for various termination scenarios:
def cleanup_handler(signum=None, frame=None):
"""Handles cleanup during shutdown, scaling down resources gracefully."""
main_actor.shutdown()
# Register cleanup for normal program exit (e.g., uncaught exceptions)
atexit_handler = lambda: cleanup_handler(None, None)
atexit.register(atexit_handler)
# Register cleanup for interrupt signals
signal.signal(signal.SIGINT, cleanup_handler) # Ctrl+C
signal.signal(signal.SIGTERM, cleanup_handler) # TERM signal
-
atexithandler: Runs cleanup when the program exits due to unexpected errors or normal completion. - Signal handlers: Run cleanup when the program is interrupted by the user (Ctrl+C, SIGINT) or the system (SIGTERM, often sent by systems).
Actor Implementation
Let’s examine how these actors are implemented at the code level.
Base Actor Class
The base actor class is inherited by all actors and is responsible for managing the actor lifecycle and the processing loop:
-
_processor(): An abstract method that must be implemented by subclasses. This is a long-running process that starts when the Main Actor prompts the worker actor to start and runs until the Main Actor signals it to stop. -
start(): Starts the actor’s processing loop by creating an async task for_processor(). -
stop(): Stops the actor’s processing loop and performs cleanup. -
ActorState: An enum that tracks the current state of the actor (INITIALIZED, READY, STOPPED, COMPLETED, etc.).
Important: Users can only start, process, or stop the Main Actor. The entire lifecycle of worker actors is managed by the Main Actor.
class BaseServiceActor:
def __init__(self, config: FeatureFetcherConfig):
self.config = config
self.actor_id = self.get_actor_id() # Gets the unique ID of this actor instance
# Relevant initialization code here
self.state = ActorState.INITIALIZED
@abstractmethod
async def _processor(self):
"""Abstract method: long-running processing loop implemented by subclasses."""
...
@check_state(ActorState.INITIALIZED)
async def start(self):
"""Starts the actor's processing loop."""
self._watcher_task = asyncio.create_task(self._processor())
self.state = ActorState.READY
@check_state(ActorState.READY)
async def stop(self):
"""Stops the actor's processing loop and performs cleanup."""
self.state = ActorState.STOPPED
# Cleanup code here (close connections, flush buffers, etc.)
Ray Async Actors are actors where communication happens through the event loop, which is intrinsic to the actor itself. A Python class becomes an actor when it is decorated with the @ray.remote decorator. This makes it an entity that is scalable and fault tolerant. Ray actors become async if at least one of their methods is asynchronous. It is necessary to create a new event loop for long-running tasks; otherwise, actors can become unresponsive if any task takes too long. Generally, the start method launches this long-running task in the same event loop, as it usually won’t block. This is a good point to note, even though it is not used here.
Main Actor
The Main Actor orchestrates the entire feature fetch system, managing worker lifecycle, routing events, and monitoring health.
class MainActor(BaseServiceActor):
def __init__(self, config: FeatureFetcherConfig):
super().__init__(config)
self._start_worker_actors_and_queues() # Spawn all worker actors and initialize queues
self.state = ActorState.READY
async def _processor(self):
"""Keeps workers alive until shutdown is requested."""
# Keep workers alive until user requests shutdown
while self.state != ActorState.SHUTDOWN:
await asyncio.sleep(1)
self._shutdown_workers() # Clean shutdown of all workers
@check_state(ActorState.READY)
async def _fetch_features(self, records):
"""
Main API method called by FastFeatureFetcher to start the feature fetch process.
Runs three concurrent tasks: progress tracking, feature fetching, and failure monitoring.
"""
await asyncio.gather(
self._progress_stats_calculator(), # Track progress and detect completion
self._execute_feature_fetch(records), # Process records and enqueue events
self._monitor_failures(), # Monitor worker health and handle failures
)
async def _progress_stats_calculator(self):
"""
Continuously tracks progress stats. When all work is complete,
transitions the actor to COMPLETED state.
"""
while self.state == ActorState.READY:
progress = await self.get_progress() # Get progress from all worker actors
if is_completed(progress):
self.state = ActorState.COMPLETED
break
await asyncio.sleep(1)
async def _execute_feature_fetch(self, records):
"""
Iterates through records and routes them to appropriate queues.
Skips cached feature families to avoid redundant computation.
"""
async for record in records:
if self.check_cached(record): # Skip if already computed and cached
continue
relevant_queue = self._determine_queue(record) # Route to correct queue
await put_ray_queue(relevant_queue, record)
async def _monitor_failures(self):
"""
Monitors worker actors for failures. Decides whether to stop the system
or ignore transient failures based on failure patterns.
"""
while self.state == ActorState.READY:
failures = await self.get_failures() # Check all workers for failures
if self._should_stop(failures):
self.state = ActorState.FAILED
break
await asyncio.sleep(1)
Code Explanation:
The Main Actor uses concurrent execution via asyncio.gather() to run three independent tasks simultaneously:
-
Progress Tracking (
_progress_stats_calculator): Continuously polls worker actors to get progress statistics. When all queues are empty and all work is complete and writer signals all records are processed, it transitions the actor to the COMPLETED state, signaling that the feature fetch is done. -
Record Processing (
_execute_feature_fetch): Iterates through input records asynchronously. For each record:- Checks if features are already cached (via cache file with key
(user_id, pitc_timestamp, feature_family_id)) to support resumability - If not cached, determines the appropriate queue (DynamoDB input queue, Fast Feature Service queue, or Slow Feature Service queue) based on configuration
- Enqueues the event for processing
- Checks if features are already cached (via cache file with key
-
Failure Monitoring (
_monitor_failures): Continuously monitors the health of all worker actors and also checks if the there are any problems in the features fetched. If it detects critical failures (e.g., actor crashes, repeated errors), it can decide to stop the entire system gracefully rather than continuing with degraded performance.
This concurrent design allows the Main Actor to coordinate the entire system efficiently without blocking on any single operation.
DynamoDB Processor Actor
The DynamoDB Processor Actor is responsible for fetching features from DynamoDB. It listens to the input queue and fetches features as soon as events are added.
How We Solved the Inefficiencies:
-
Reusable Client: We create the DynamoDB client object only once during actor initialization and reuse it for all requests, eliminating the overhead of creating clients per request.
-
Intelligent Batching: We batch user requests until we reach the maximum batch size of 100 records. The batching logic is adaptive:
- If each user requires 10 feature families, we batch 10 users together (10 users × 10 families = 100 items).
- If each user requires 80 feature families, we send 1 user per
batch_get_itemrequest (80 items).
This intelligent batching maximizes DynamoDB’s capacity while minimizing request overhead. These optimizations alone yielded approximately 6× speedup in the DynamoDB fetcher component.
class DynamoDBProcessorActor(BaseServiceActor):
def __init__(self, config: FeatureFetcherConfig):
super().__init__(config)
self.dynamo_db_client = DynamoDBClient()
async def _processor(self):
while self.state == ActorState.READY:
record = await get_ray_queue(self.input_queue)
hit, miss = await self.fetch_features_from_dynamo(record)
await put_ray_queue(self.writer_queue, hit)
if miss:
fs_queue = self._decide_fs_queue(miss) # Fast or slow queue
await put_ray_queue(fs_queue, miss)
async def fetch_features_from_dynamo(self, record):
return await self.dynamo_db_client.batch_get_item(record)
Code Explanation:
The DynamoDB Processor follows a simple but effective loop:
- Dequeue: Pulls events from the input queue (asynchronously waits if queue is empty).
- Fetch: Queries DynamoDB using
batch_get_itemwith optimized batching. - Route Results:
- Cache hits (features found in DynamoDB) → sent directly to Writer Queue.
- Cache misses (features not in DynamoDB) → sent to Feature Service Queue (fast or slow based on feature family characteristics).
This design decouples DynamoDB fetching from Feature Service fetching, allowing both to run in parallel across different actors.
Feature Service Processor Actor
The Feature Service Processor Actor is responsible for fetching features from the Feature Service. It listens to both the fast queue and slow queue, fetching features as soon as events are added. The actor uses a semaphore design pattern to control concurrency levels for fast and slow requests independently.
class FeatureServiceProcessorActor(BaseServiceActor):
def __init__(self, config: FeatureFetcherConfig):
super().__init__(config)
self.feature_service_client = FeatureServiceClient()
# Semaphores control maximum concurrent requests for each queue type
self.fast_semaphore = asyncio.Semaphore(config.max_concurrent_fast_requests)
self.slow_semaphore = asyncio.Semaphore(config.max_concurrent_slow_requests)
async def _processor(self):
fast_task = asyncio.create_task(self._process_events(self.feature_service_queue_fast, is_slow=False))
slow_task = asyncio.create_task(self._process_events(self.feature_service_queue_slow, is_slow=True))
await asyncio.gather(fast_task, slow_task)
async def _process_events(self, queue, is_slow):
while self.state == ActorState.READY:
event = await get_ray_queue(queue)
if is_slow:
for feature_family in event.feature_families:
await self.slow_semaphore.acquire()
task = asyncio.create_task(
self.fetch_features_from_feature_service(feature_family)
)
task.add_done_callback(lambda _: self.slow_semaphore.release())
else:
await self.fast_semaphore.acquire()
task = asyncio.create_task(
self.fetch_features_from_feature_service(event)
)
task.add_done_callback(lambda _: self.fast_semaphore.release())
async def fetch_features_from_feature_service(self, event):
"""Fetches features from Feature Service via HTTP request."""
return await self.feature_service_client.fetch_features(event)
Semaphore Design Pattern Explanation
The semaphore pattern is crucial for controlling concurrency and preventing the Feature Service from being overwhelmed:
-
What is a Semaphore? A semaphore is a synchronization primitive with a counter. When you acquire a semaphore, the counter decreases; when you release it, the counter increases. If the counter reaches zero, further acquire attempts block until a release occurs.
-
Why Two Semaphores? We use separate semaphores for fast and slow queues to control their concurrency independently:
- Fast Semaphore: Limits concurrent batched requests (e.g., 1000 concurrent requests).
- Slow Semaphore: Limits concurrent individual slow requests (e.g., 200 concurrent requests).
-
How It Works:
- When a task wants to make a request, it first acquires the appropriate semaphore (blocks if limit is reached).
- The task executes and fetches features.
- When the task completes (success or failure), it releases the semaphore via a callback, allowing another task to proceed.
This pattern ensures we maximize Feature Service utilization without overloading it, while maintaining separate concurrency budgets for different request types.
Advantage of Two Queues
Using two separate queues in Fast Feature Fetch optimizes both efficiency and scalability. Fast feature families are processed together in batches so they aren’t delayed by slow ones, while slow feature families (like those requiring complex regex, I/O operations) are each sent as parallel requests to avoid bottlenecks. A single queue would mean slow features stall everything, but splitting all features individually would overwhelm the service. The optimal balance is when for a user a request is split into 1 fast family features and x slow family features, such that both takes equal amount of time to complete. By doing this, we can minimize the number of requests to the Feature Service and also compute features at best possible speed. Impact:
This approach delivered massive improvements:
- 4× reduction in feature fetch time per user
- CPU utilization increased to 100% in Feature Service (previously ~40%)
- 90% reduction in total requests to Feature Service
- 2× reduction in memory usage (fewer threads needed)
The reduced memory footprint allowed us to switch from memory-optimized to compute-optimized instances, increasing CPU per pod and further reducing costs.
Sharing Connections in Feature Service Processor
HTTP connection overhead is significant when making thousands of requests. By default, each HTTP request would open a new TCP connection, perform a TLS handshake, make the request, and close the connection. This overhead can be 10-50ms per request.
Connection Pooling with aiohttp:
We use aiohttp.TCPConnector to create a connection pool that’s shared across all requests. This means:
- Connections are reused across multiple requests
- DNS lookups are cached
- TCP and TLS handshakes are amortized across many requests
# Create a connection pool with limits matching our concurrency
connector = aiohttp.TCPConnector(
limit=config.max_concurrent_fast_requests + config.max_concurrent_slow_requests,
ttl_dns_cache=config.TTL_DNS_CACHE, # Cache DNS for 10 minutes
keepalive_timeout=config.KEEPALIVE_TIMEOUT, # Keep connections alive for reuse
force_close=False, # Don't force close; allow connection reuse
enable_cleanup_closed=True # Clean up closed connections automatically
)
# Create a single session that all requests share
session = aiohttp.ClientSession(connector=connector)
async def fetch_features_from_feature_service(url, payload):
"""
Makes an HTTP request using the shared session and connection pool.
The connection is automatically returned to the pool after use.
"""
async with session.post(url, json=payload) as resp:
response_text = await resp.text()
return response_text
# Process events, reusing connections from the pool
async for event in events_to_process:
task = asyncio.create_task(fetch_features_from_feature_service(event.url, event.payload))
task.add_done_callback(lambda t: self._handle_response(t.result()))
Why This Speeds Things Up:
- Connection Reuse: By reusing existing connections, we significantly reduce the overhead that would otherwise be spent opening and closing connections for every request.
- DNS Caching: DNS lookup results are cached, eliminating repeated network calls for domain resolution and speeding up subsequent requests.
- TCP Keep-Alive: Keeping TCP connections open between requests avoids the repeated cost of establishing new connections, making the workflow more efficient.
- TLS Session Resumption: Secure sessions can be resumed for subsequent requests, avoiding repeated cryptographic handshakes.
Connection pooling across large numbers of requests offers substantial time savings by minimizing overhead for each individual request.
File Writer Actor
The File Writer Actor is responsible for writing fetched features to files. It listens to the writer queue and writes features asynchronously, which is crucial for maintaining high throughput in the system.
Challenges with Multiple Writers:
If we scale up the File Writer Actor (multiple instances), they could potentially write to the same file simultaneously, causing race conditions and data corruption. Our solution:
- Per-Actor Files: Each File Writer Actor writes to its own file, identified by
actor_idand arandom_idand file_counter to ensure uniqueness. - Buffering: Features are buffered in memory and written in batches, reducing the number of I/O operations.
- Async I/O: All file operations are asynchronous, preventing the actor from blocking while waiting for disk I/O.
class FileWriterActor(BaseServiceActor):
def __init__(self, config: FeatureFetcherConfig):
super().__init__(config)
# Create unique file path for this actor to avoid race conditions
self.output_file = f"{config.output_dir}/features_{self.actor_id}_{uuid.uuid4()}_{file_counter}.parquet"
self.buffer = []
self.buffer_size_limit = config.write_buffer_size
async def _processor(self):
"""
Main processing loop: dequeue features, buffer them, and write when buffer is full.
"""
while self.state == ActorState.READY:
event = await get_ray_queue(self.writer_queue)
self.put_to_buffer(event)
if self.buffer_is_full():
await self.write_buffer_to_file()
async def write_buffer_to_file(self):
await self.file_writer.write_feature_buffer()
await self.update_cache_file()
await self.sync_file_to_remote()
The FileWriterActor class manages writing fetched features to disk efficiently and safely in a distributed, high-throughput system. To avoid file corruption when scaling to multiple actors, each actor writes to its own unique output file, leveraging identifiers like actor_id, a random UUID, and a file counter for naming. Features are not immediately written; instead, they accumulate in an in-memory buffer until a specified size is reached, at which point they are written out in batches. This minimizes frequent disk I/O. All file operations are asynchronous, ensuring the actor remains highly responsive and does not block on potentially slow disk writes. This design supports smooth parallel processing, safeguards data integrity, and maximizes system throughput.
Conclusion
Through careful analysis and architectural redesign, we built Fast Feature Fetch, a distributed, parallel system that achieves an 8× speedup in feature fetching. What previously took 72 hours for 1M samples now completes in approximately 10 hours. It is production-ready and has been processing millions of feature fetches reliably.